Two jobs, two processes: why Multigres has its own connection pooler
Why Multigres splits client acceptance (multigateway) from backend pooling (multipooler) instead of using a single-process pooler like PgBouncer.
Most connection poolers do two jobs in one process: accept client connections, and manage backend connections. In Multigres, we split them. Multigateway accepts clients; multipooler manages backends. This post is about why.
What is Multigres?
Multigres is Vitess for Postgres. It provides horizontal scaling, connection pooling, and cluster orchestration for PostgreSQL deployments, the same set of problems Vitess has been solving for MySQL for more than a decade.
A Multigres cluster is made of a few coordinated services. Multigateway sits at the front, accepting client connections, speaking the Postgres wire protocol, and routing incoming queries to the right backend. Multipooler sits in front of each Postgres instance and manages the pool of backend connections to it - one multipooler per Postgres instance, colocated. Multiorch runs cluster orchestration: leader election, failover, and health monitoring. Underneath, your data is sharded across multiple Postgres instances, with the cluster topology stored in etcd. The full tour is in the architecture overview.
Within each shard, one Postgres instance is the leader - it accepts writes - while the others run as replicas that serve reads and stand by to take over. Multiorch watches the cluster and, when a leader fails or is being decommissioned, promotes a replica to take its place. Multigateway and multipooler need to know about these transitions as they happen - which instance is the current leader, when leadership is changing hands, when to drain in-flight requests - so they can route traffic correctly and not lose work during a handover. We'll lean on these terms - leader, replica, promotion, drain - throughout the rest of the series.
For this post, what matters is that Multigres ships its own connection pooler - instead of bolting on PgBouncer. That's the part that surprises people. Postgres has PgBouncer. PgBouncer works. Why build another one?
Why not PgBouncer?
Before we go any further: PgBouncer is excellent. Many people reading this probably operate it every day and have strong, well-earned opinions about it. The reason Multigres has its own pooler is that we want the pooler to be deeply integrated with the rest of the cluster.
A Multigres cluster is a coordinated thing. Postgres instances come and go. Primary and replica roles flip during failover. Backups run on schedule and have to be coordinated with traffic. Multiorch, the orchestration component, needs to drain in-flight requests before promoting a new leader.
A pooler in this world has to participate in cluster coordination. When multiorch decides a Postgres instance should stop accepting writes, the pooler is what closes existing client transactions cleanly and refuses new ones, while multigateway starts buffering these requests. When a backup is in flight, the pooler knows. When a replica is promoted to primary, the pooler knows. When the cluster is doing a graceful shutdown, the pooler is the choke point that decides when "graceful" is actually safe.
PgBouncer is a sidecar. It can be configured, restarted, monitored, but it doesn't speak the cluster's coordination language. We needed something that does.
You might ask: why not contribute these capabilities upstream to PgBouncer? Honestly, the changes we'd need - cluster integration, the gateway/pooler split, full extended-protocol fidelity, plus everything else this series covers - together amount to a fork, not a patch. PgBouncer is excellent at what it sets out to do, and we didn't want to push it into being something it isn't. Building our own is the price of cluster integration.
Why split into two services?
Once we accept that we're building our own pooler, the next question is: what shape should it have? One process, or two?
Multigres' goal is to bring sharding to Postgres, which makes it a distributed database. And a distributed database changes the connection-layer requirements in two ways.
A single client connection has to reach any Postgres instance in the cluster. When a query arrives, the system might need to send it to one specific Postgres instance, or fan it out across many of them, depending on the data layout. The client doesn't, and shouldn't, know or care which one. That requires a process that owns the client connection and decides where queries go, independently of the Postgres instances themselves.
Aggregation happens at the top. A query that touches multiple shards needs its results combined before they go back to the client. That combine-the-results step is logically separate from any individual Postgres instance's connection pool. It belongs in a layer above all of them.
Both of those concerns naturally live in one process: a thing that accepts client connections, parses queries, decides where they go, and assembles their results. That's multigateway.
What's left is the per-Postgres-instance connection pool, a thing that holds open backend connections to one Postgres instance, hands them out to incoming requests from gateways, and manages their lifecycle. That's multipooler. One per Postgres instance, colocated with it.
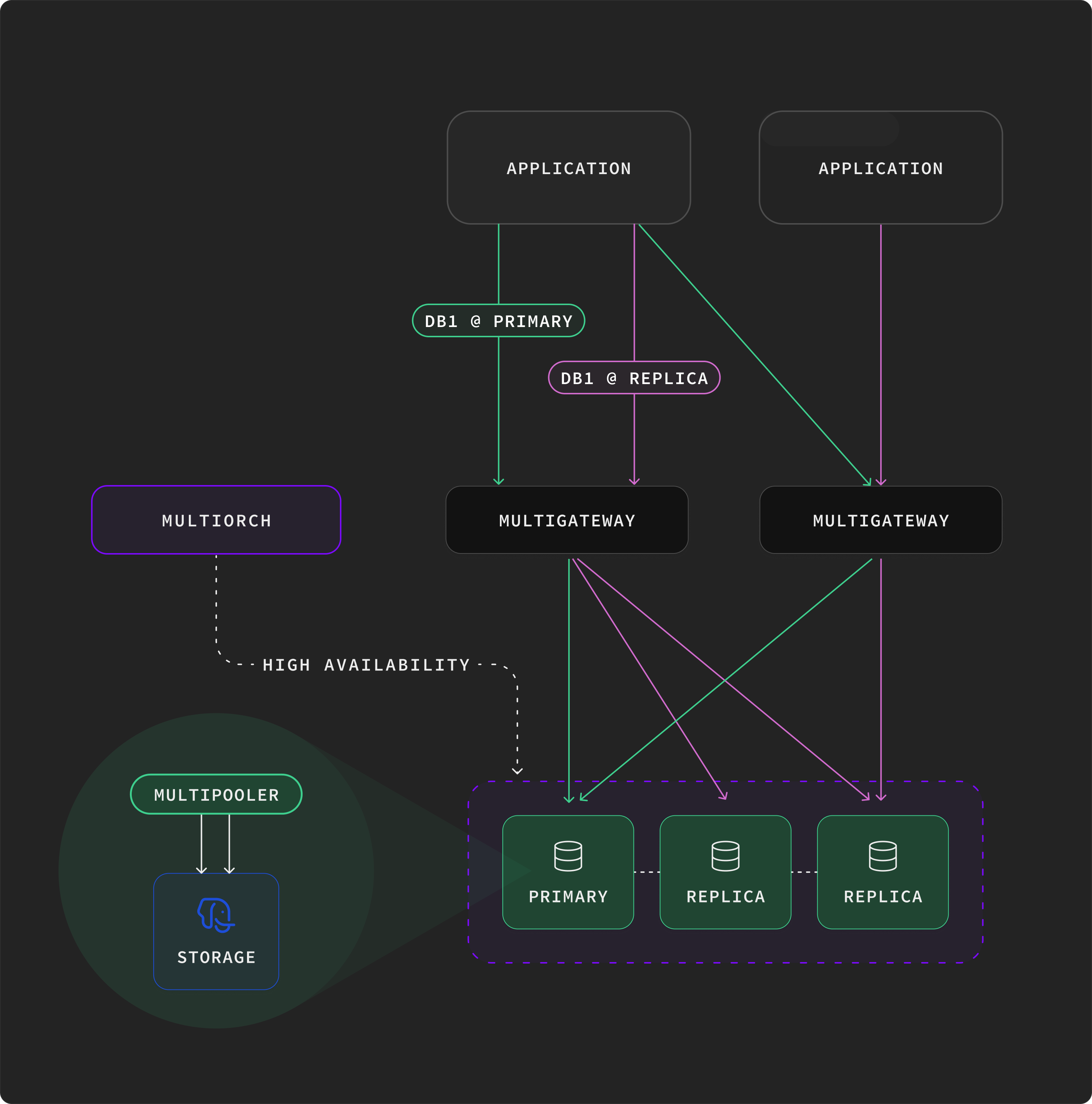
The split has a useful side effect for scaling. The number of client connections is determined by your application's connection count, which can run into the millions for a busy product. The number of backend connections per Postgres instance is much smaller, typically a few hundred, sometimes a couple thousand. Multigateway scales horizontally with client connection count; multipooler scales with the number of Postgres instances. Each tier scales along the dimension that actually matters for that tier.
What we gave up
It would be dishonest not to acknowledge: this shape costs us things.
You now operate two services where a single PgBouncer would do, and they have to be deployed, monitored, and upgraded as a coordinated unit. There's also an extra hop on the hot query path - gateway to pooler over gRPC - before the query reaches Postgres. It's a small hop, since multipooler is colocated with the Postgres instance, but it's a hop nonetheless. And our pooler does a few extra things compared to a vanilla pooler, tracking per-user pools, interning session settings, consolidating prepared statements, which the rest of this series gets into.
We accept these costs because we're building a single cohesive product that takes all the pain points of running Postgres away.
Connection pool features
With the architectural shape settled, here are a handful of features in the connection pool that are worth a closer look.
Per-user connection pools
Multigres maintains a separate connection pool per user, no shared pool, no SET ROLE impersonation. The reason we made that choice, the algorithm that splits a fixed connection budget fairly across users, and the routing trick that keeps pool lookup fast all live in the deep-dive post: Per-user pools that share fairly. (Read more)
Pooling without choosing a mode
PgBouncer lets you pick a pool mode - transaction, session, or statement - globally or per database. Each one has its tradeoffs. If you want temp tables to work, you have to run in session mode, where connections are held for the entire client session, and your connection reuse, along with your performance under load, suffers for it. If you want maximum reuse, transaction mode is faster, but it silently breaks anything that depends on session state. Statement mode goes even further in that direction.
We didn't want users to have to choose. Multigres is smart enough to figure out, on its own, which mode of behavior a given query needs, and to release a connection back to the pool the moment it's actually safe to do so. Most queries get reuse comparable to statement mode; the ones that genuinely need session-mode or transaction-mode safety get it, automatically.
The deep-dive post covers what the pool tracks to make those decisions, and how it handles the edge cases: Pooling without choosing a mode. (Read more)
Prepared statement consolidation across gateways
Multigres deduplicates prepared statements across gateways - Postgres parses, plans, and caches a given statement once, no matter how many gateways are forwarding it. Why this matters, how the dedup spans both multigateway and multipooler, and what it costs all live in the deep-dive post: One parse per query, no matter how many gateways. (Read more)
Beyond these three, the pool also gives you full extended-query-protocol fidelity and rich observability into what it's doing, but the three above are the ones worth further exploration.
What's next in this series
Over the next three posts, we will go into more detail about the Multigres connection pooler:
- Per-user pools that share fairly - how Multigres gives every user a dedicated pool, splits the connection budget fairly across them, and keeps pool routing fast.
- Pooling without choosing a mode - how the pool gets transaction-mode speed and session-mode safety at the same time, without making you choose between them.
- One parse per query, no matter how many gateways - how Multigres makes sure Postgres parses a given statement only once, no matter how many gateways are forwarding it.
If any of this resonates, or if you have ideas on how we can improve our current offering, open an issue or a PR at github.com/multigres/multigres. We'd love to hear from you.