One parse per query, no matter how many gateways
Deduplicating prepared statements across many multigateways so Postgres parses each query once, not once per gateway.
In a single-database setup, prepared statements are a clean win. Postgres parses the statement once, builds a plan, caches both, and subsequent EXECUTEs reuse the plan. Cheap. In a setup with many gateways in front of one Postgres instance, that win quietly evaporates unless you do something about it. This post is about what we do about it.
The N-gateways problem
Imagine an application server that issues a prepared statement:
PREPARE find_user (int) AS SELECT * FROM users WHERE id = $1;
EXECUTE find_user(42);Now scale that up. You have ten multigateways behind a load balancer. Your app reconnects after a brief network blip and lands on a different gateway. The new gateway has no idea about your prepared statement, so it forwards a fresh PREPARE to whatever multipooler it's talking to. Postgres now has two copies of find_user - one from the original connection, one from the new one.
Multiply by N gateways and the rate of client reconnects, and you can end up with many duplicates of the same logical statement on the Postgres backend. The plan cache fills up. Memory usage on the Postgres instance climbs. Parses repeat for queries that should have been parsed once.
This isn't a problem at small scale. It becomes one at the scale a distributed database is supposed to handle.
Why neither layer alone can fix it
There's a temptation to fix this in a single layer.
If we tried to fix it in the gateway, each gateway would need to know what every other gateway has prepared. That requires distributed coordination - gateways gossiping with each other, or a shared cache that all of them write to. Both options are hard to get right under high churn (gateway scale-out, scale-in, restart) and they introduce a critical dependency between gateways that we'd like to avoid.
If we tried to fix it in the pooler, we'd need to track per-client prepared statement names - but the pooler doesn't see clients directly. It sees gateways. From the pooler's perspective, two gateways forwarding PREPARE foo look like two unrelated PREPARE foo requests, even though they came from one logical client.
The fix has to span both layers, because the information is split across both layers. The gateway is the only thing that sees the client. The pooler is the only thing that sees the Postgres backend.
How the dedup actually works
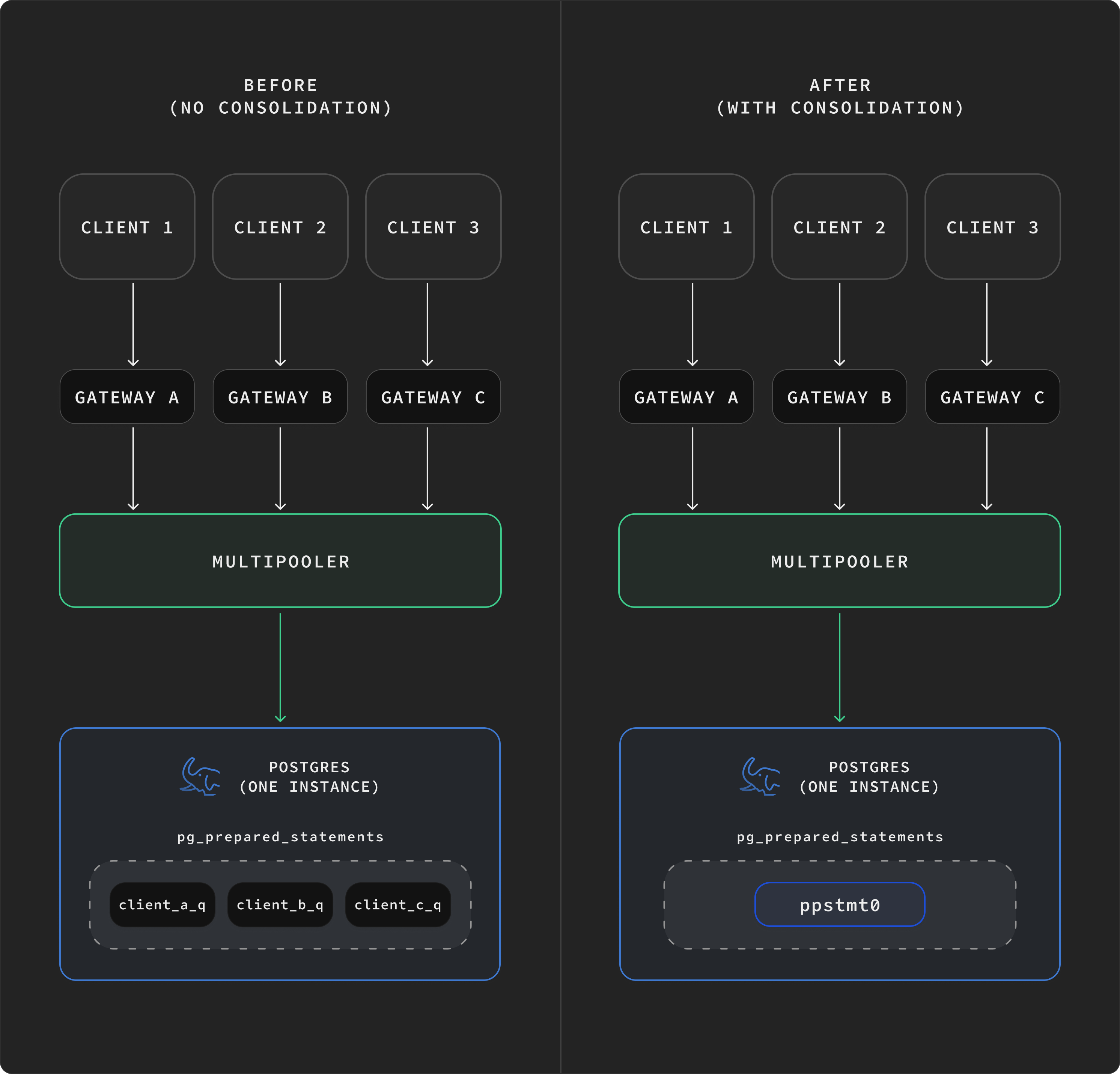
In Multigres, prepared statement consolidation works in two halves.
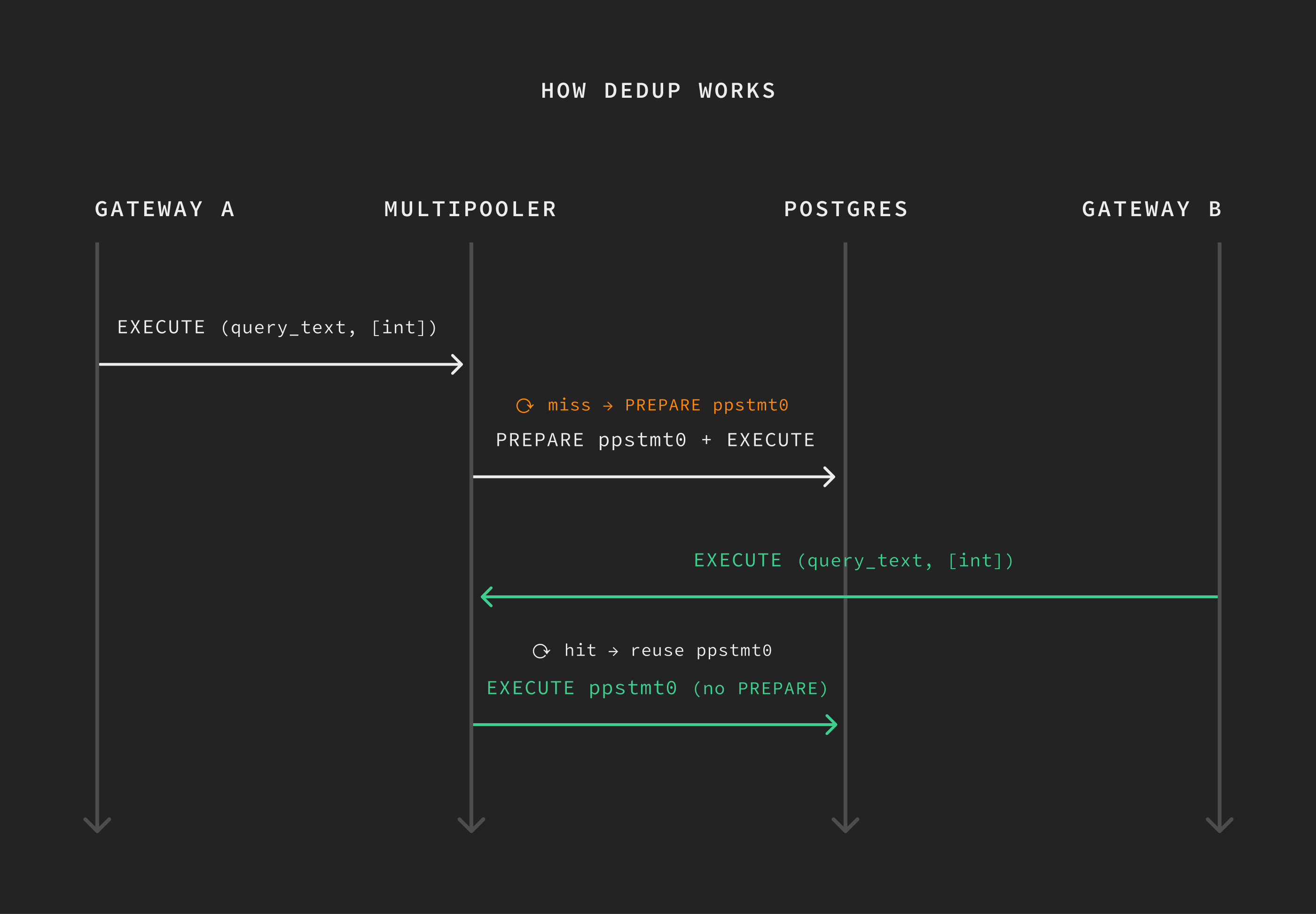
Gateway side. When a client issues PREPARE my_query AS …, multigateway records the mapping locally: (client_session, my_query) → (query_text, param_types). The client's name (my_query) is meaningful only to that client; Multigres doesn't promise it'll be my_query on the backend.
Pooler side. When multigateway forwards the EXECUTE to multipooler, it sends the actual (query_text, param_types) along with it. Multipooler maintains a map: (query_text, param_types) → canonical_name. If we've seen this query before, we reuse the existing canonical name and just send EXECUTE. If we haven't, we issue a PREPARE canonical_name AS … to the backend, store the mapping, and then EXECUTE. (The diagram shows SQL-style PREPARE for readability; the wire-level mechanism is the extended-protocol Parse message.)
The canonical name is generated by multipooler and stable across all backend connections it manages - every connection uses the same ppstmt0 for the same logical statement. Each backend connection still needs to execute its own Parse the first time ppstmt0 is used on it, since Postgres prepared statements are connection-scoped, but the name is shared. Multiple clients with multiple gateway-side names - my_query, find_user, q42 - all collapse to that one canonical name, as long as the underlying query text and parameter types match.
The result: each backend connection parses each unique (query_text, param_types) exactly once, and every connection agrees on what to call it. The plan cache holds at most one entry per backend connection per logical statement - not the gateway-count × client-name-count blowup you'd get without consolidation.
Memory model
The pooler's (query_text, param_types) → canonical_name map is bounded by the application's distinct query surface, not by the number of clients or gateways. A typical application might have a few hundred distinct prepared statements; a complex one might have a few thousand. Either is fine.
The map is currently unbounded - we don't evict canonical names. If we did, we'd have to invalidate any client references to the evicted statement, and that gets complicated quickly. Better to let the map grow with the app's natural query surface and trust that surface is bounded.
For pathological apps with millions of distinct queries, this would eventually become a problem. The obvious fix, when we get there, is an LRU cache on top of the canonical-name map - bound the size, evict the least-recently-used entries. That trades unbounded memory for churn: an evicted entry's next use triggers a fresh parse on the backend. Worth it when memory is the binding constraint, but not before. We haven't seen the issue in practice yet, so for now we're kicking the can down the road.
The one cost worth flagging
Backend introspection shows canonical names. If you query pg_prepared_statements on the backend or look at pg_stat_statements, you'll see canonical names like ppstmt0 rather than the names your application chose. For most workflows this is fine; for query attribution or debugging it's a small extra step.
Wrapping up
That's the four-post tour:
- Two jobs, two processes: why Multigres has its own connection pooler - the architecture and motivation.
- Per-user pools that share fairly - security, fair sharing, and reuse across session settings.
- Pooling without choosing a mode - transaction-mode speed and session-mode safety, automatic.
- This post - one parse per query, no matter how many gateways.
Connection pooling looks simple from the outside - a few sockets, a pool, some bookkeeping - but a distributed database changes every assumption about it. Multigres is our attempt at getting it right. If you have a take on what we did, or didn't do, open an issue or a PR. We'd love to hear it.