Per-user pools that share fairly
Why Multigres pools connections per user, how pools share Postgres's connection budget fairly, and constant-time routing at scale.
Multigres maintains a separate connection pool per user. This post is about why we made that choice (it's mostly a security story), how we share the connection budget fairly across users, and the routing trick that keeps pool lookup constant time even when there are many pools.
Why per-user pools
The natural shape of a single shared pool is to connect as one privileged user, then SET ROLE to whichever user a request belongs to. Most poolers do this. It works, but it carries a real security risk.
The pool user has to have privileges to switch role to any user the system might serve. If a malicious user finds a way to issue their own SET ROLE, through a function, a procedure, or any path the pool fails to catch - they're suddenly running as someone else. The pool's broad privilege becomes theirs. It's a privilege-escalation surface that doesn't need to exist.
Per-user pools sidestep the problem. Each user gets their own pool, and the pool's backend connections are authenticated as that user. There's no impersonation at all, because there's no privileged role to impersonate from. Every backend connection has exactly the privileges of the user it serves, and nothing more.
It also makes the security audit easier. If you look at any backend connection's session, you can see - directly, with no extra reasoning - which user it serves and what they can do. There's no "this connection is owned by pool_user, but the active role inside it is alice" indirection.
Sharing the connection budget
Per-user pools come with a real cost: you now have many pools where you used to have one. Postgres still has a hard limit on how many connections it can handle (the max_connections setting), and that limit is the same whether you use one big pool or fifty per-user pools. So if a noisy user opens lots of expensive queries, they could in principle starve the others of available backend connections.
I've long been a huge fan of how the network layer thinks about resource fairness. Network folks have been working on how to share a fixed pipe across many flows for decades, and one of the cleanest answers they've landed on is max-min fairness. So we picked it up for the connection pool.
The intuition is simple: maximize the minimum allocation that any user gets. Concretely, the algorithm finds the user with the smallest demand and allocates that amount to everyone. Among the users who still want more, it finds the next smallest demand and brings everyone in that group up to that level. It keeps going until either everyone is satisfied or the pool runs out.
Max-min fairness in action with a pool of 12 connections and three users — alice (demand 2), bob (demand 5), charlie (demand 10):
Round 1. Smallest demand among all three is alice's 2. Allocate 2 to everyone → alice=2 (satisfied), bob=2, charlie=2. Used: 6.
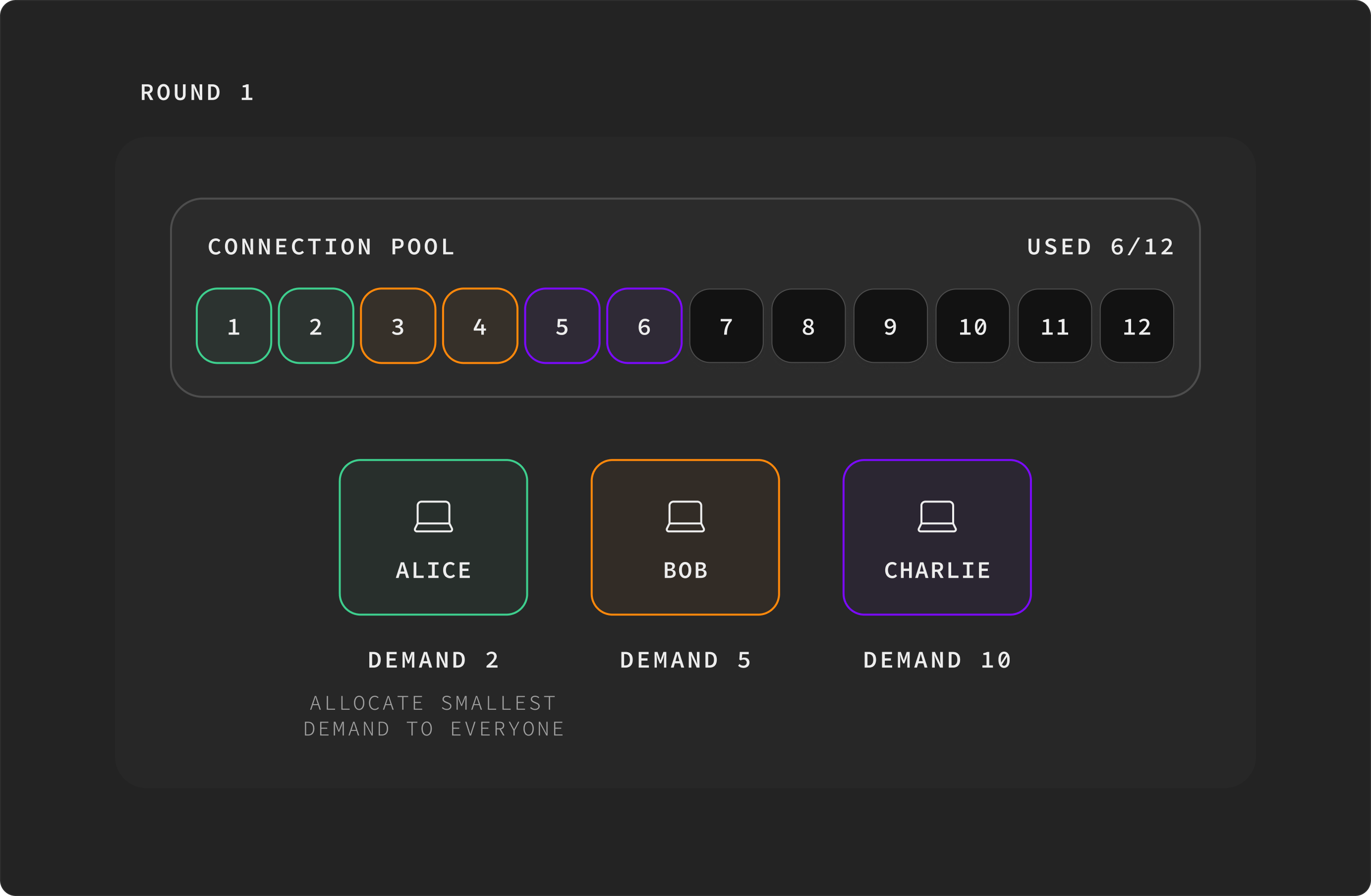
Round 2. Among bob and charlie (still wanting more), smallest demand is bob's 5. Bring both up to 5 → bob=5 (satisfied), charlie=5. Used: 12.
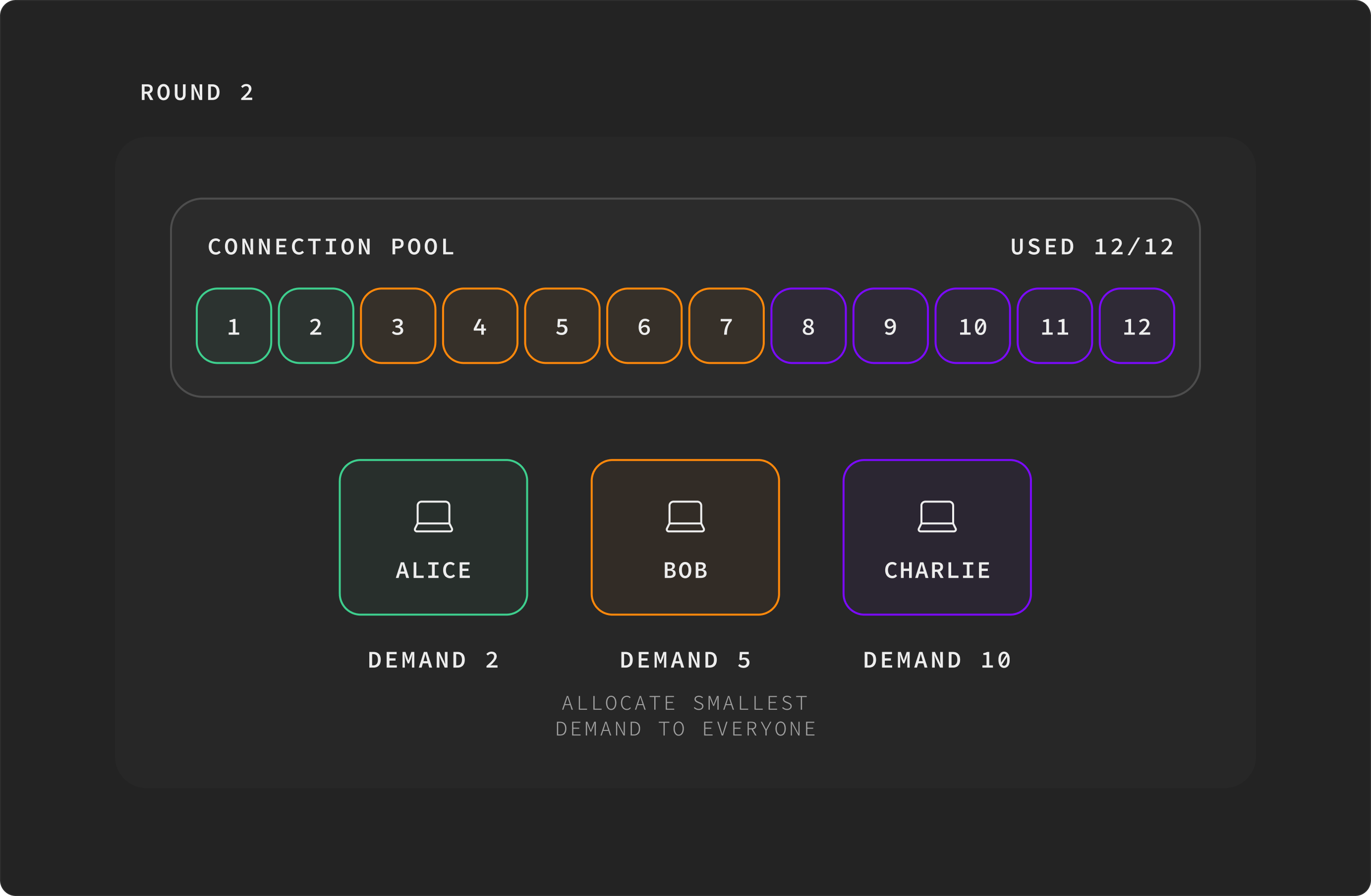
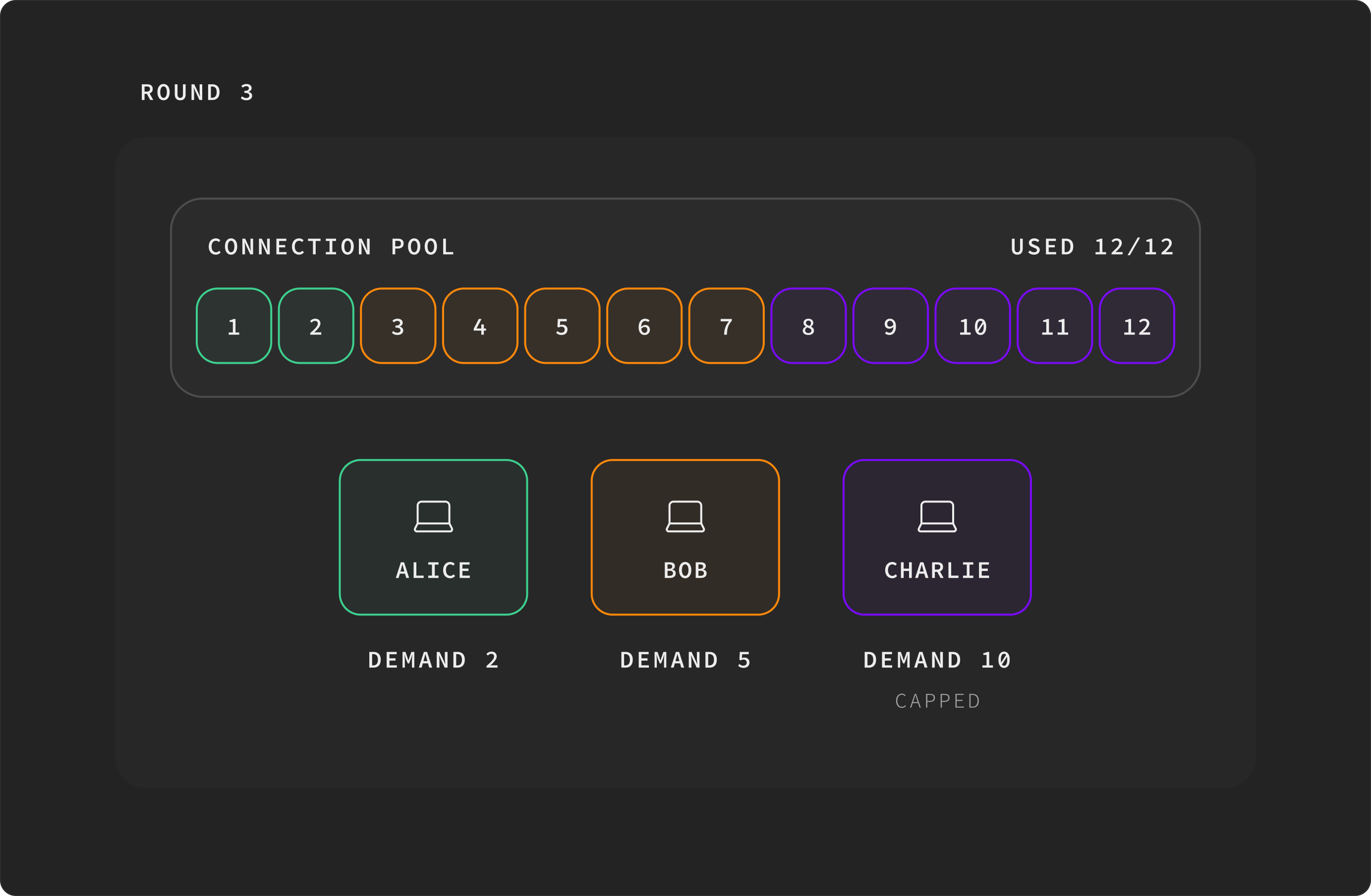
Round 3. Only charlie still wants more, but the pool is exhausted. Algorithm halts. Final: alice=2, bob=5, charlie=5.
Summarized across all three rounds:
| Round 1 | Round 2 | Round 3 | Final | |
|---|---|---|---|---|
| Alice (d=2) | 2 | - | - | 2 |
| Bob (d=5) | 2 | +3 | - | 5 |
| Charlie (d=10) | 2 | +3 | capped | 5 |
| Used | 6/12 | 12/12 | 12/12 | 12/12 |
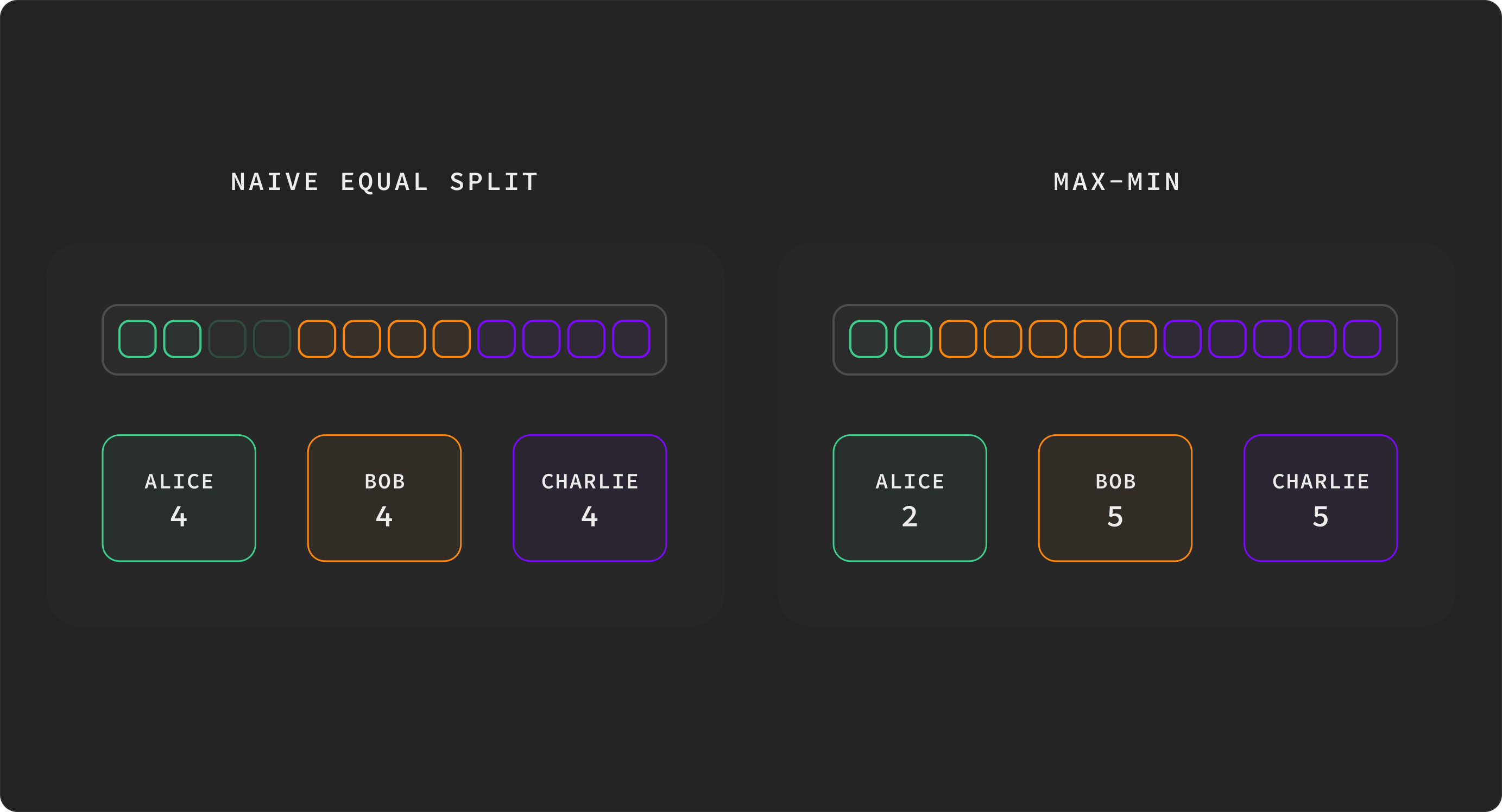
A naive equal split would give alice=4, bob=4, charlie=4 - wasting 2 of alice's slots while bob and charlie still want more. Max-min redistributes that slack: same total budget, no waste.
The benefits are concrete:
- Noisy neighbors stay contained - one user's bad day doesn't tank everyone else's.
- Pareto optimal - it's impossible to increase one user's allocation without reducing another user's.
- No incentive to game the allocator - claiming more than your fair share doesn't get you more.
As a concrete example, in a naive system that allocates by raw demand, a user could spawn ten copies of the same query, take the first result that comes back, and effectively claim ten slots' worth of priority. Max-min sidesteps that entirely: the allocator caps you at whatever the other users aren't using. Strategy-proof, for free.
Multigres tracks demand per user - how many connections each user is currently waiting on, and how many they're actively using - and rebalances on a regular cadence. The rebalancing itself runs in its own goroutine, off the hot path. Connection acquisition only ever reads the latest computed limits; it never has to wait for the allocator to recompute. The fairness machinery stays out of the way of the queries it's protecting.
Same user, different sessions
There's another wrinkle. Two queries from the same user aren't always interchangeable, because Postgres connections carry session state - things like search_path, timezone, statement_timeout, and more.
If alice has set search_path = 'analytics' on one connection and search_path = 'reporting' on another, those connections aren't substitutable. A query that relies on the analytics search path can't be served by the reporting connection, even though both belong to alice.
So per-user pools further subdivide by session settings. Each user, for each unique combination of session settings they've used, has connections in the pool that already have those settings applied. A query lookup is therefore: find user → find a connection that matches the requested settings.
The matching part is where the design gets interesting.
Bucketing connections by settings
The connection pool is organized as eight independent stacks of connections (plus a separate "clean" stack for fresh connections with no state applied). Each stack has its own mutex and its own list of connections.
When a connection has session settings applied, it lives in one of the eight stacks — picked by hashing its settings to a number from 0 to 7. The same settings always hash to the same stack: each distinct combination of session settings is assigned a stable bucket number the first time we see it, and we use the low three bits (bucket & 7) to pick the stack. This whole interning-and-bucketing pattern is borrowed wholesale from Vitess, which has been using it for years.
A worked example. Say alice uses two distinct session-setting combinations regularly: search_path = 'analytics' and search_path = 'reporting'. Bucket numbers are assigned in order, the first time each new combination is seen — so the exact numbers depend on what the rest of the cluster was doing before. Suppose alice's two combinations were the 17th and 22nd distinct settings the pool ever saw; they land in stacks 1 and 6 (17 & 7 = 1, 22 & 7 = 6). Every connection alice opens for analytics goes into stack 1; every connection she opens for reporting goes into stack 6. When a new query for analytics arrives, we go to stack 1, pop a connection, and most of the time it's already in the right state.
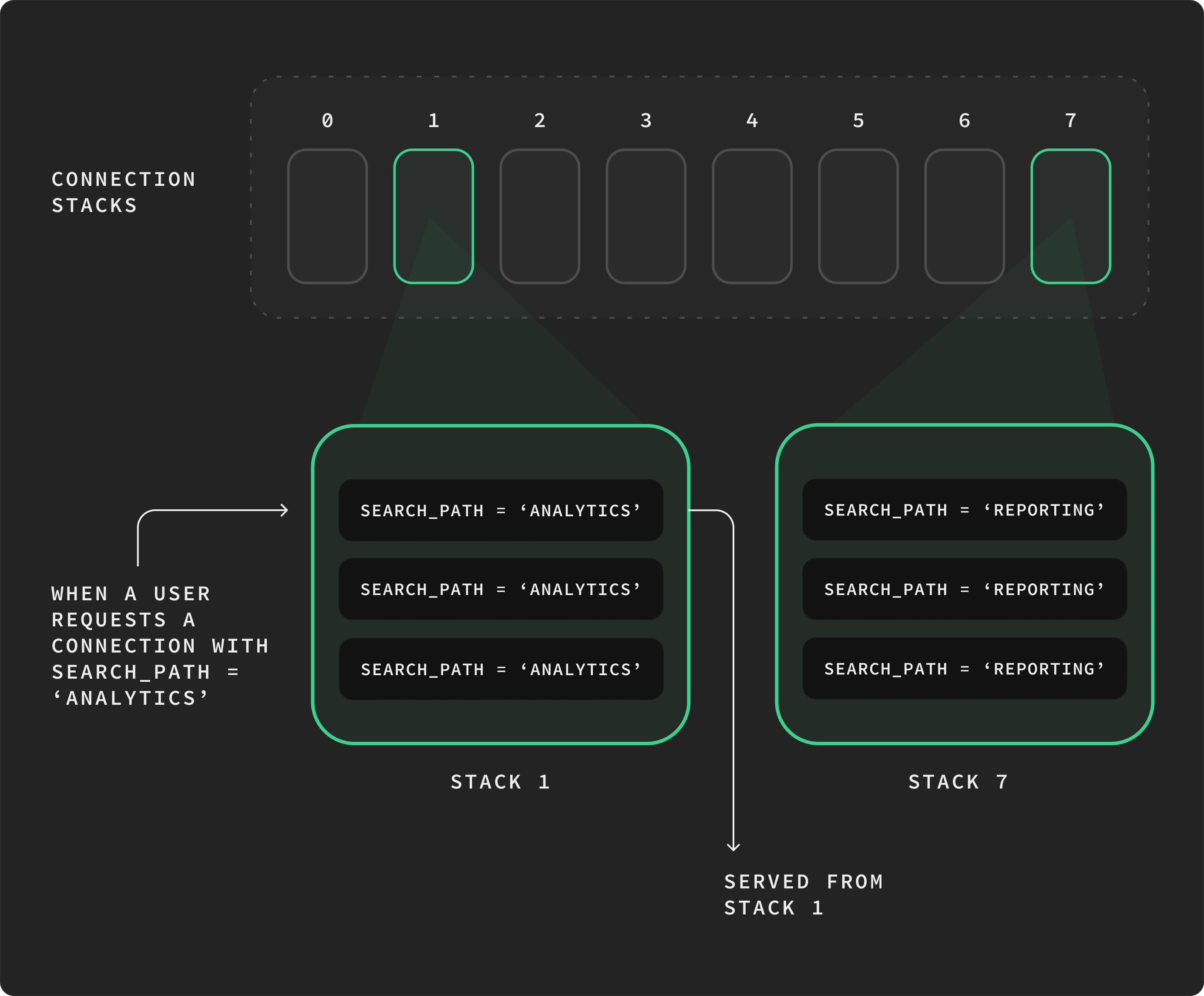
Two practical wins fall out of this:
- Connections cluster by settings. A query for a hot setting usually finds a connection in its assigned stack with the right state already applied, no reset needed.
- Concurrent access without contention. Eight independent stacks means up to eight goroutines can be popping connections at the same time without competing for a single lock.
It isn't always a perfect match. Distinct settings can hash to the same stack, there are eight stacks but unbounded distinct settings, so a stack might hold connections of mixed settings. When that happens, the pool verifies the actual state and resets the connection if it doesn't match. Bucket assignment is best-effort, not a strict guarantee.
Why eight stacks specifically? It's a tradeoff. Fewer, and connections of unrelated settings collide constantly, forcing more resets. More, and the pool fragments, each stack becomes too small to be useful, and connection acquisition frequently misses the right stack. Eight is the sweet spot Vitess landed on, and we found no reason to deviate.
The bucket-number table itself sits behind a bounded LRU, since settings combinations are theoretically unbounded (an adversarial app could SET search_path to arbitrarily long values). When the LRU evicts a setting, the next time we see it we assign a fresh bucket number and start over.
What this costs
A few honest costs of this design:
Bucket collisions force resets. With eight stacks and an unbounded number of distinct settings, multiple settings inevitably hash to the same stack. When a query pops a connection from its assigned stack, the connection at the top might have the wrong state, and we have to issue an extra round-trip to Postgres to reset it before handing it over.
Interning is by string, not by semantics. Two textually different settings ('public,private' vs 'public, private') get different bucket numbers and may land in different stacks, even though Postgres would treat them identically. The pool's bucket-collision recovery handles this fine, it just resets and reapplies, so it's a missed reuse opportunity, not a correctness bug.
Rebalancing churns connections. When the allocator gives one user more capacity and another less, the loser's pool has to close connections and the winner's pool has to open new ones. Reopening means a fresh TCP connection and authentication round-trip to Postgres. We don't pay raw connection-count overhead, every user-pool would stay warm regardless, but we do pay this churn cost whenever the workload shifts.
What's next
That's the "how do we hand out a connection?" half of the story. The next post is the "when do we get the connection back?" half.
Pooling without choosing a mode - how Multigres gets transaction-mode speed and session-mode safety at the same time, with no upfront mode choice.
If you've built connection pools, fairness allocators, or anything bucket-sharded, and made different tradeoffs than we did, we'd genuinely love to compare notes. Find us at github.com/multigres/multigres.